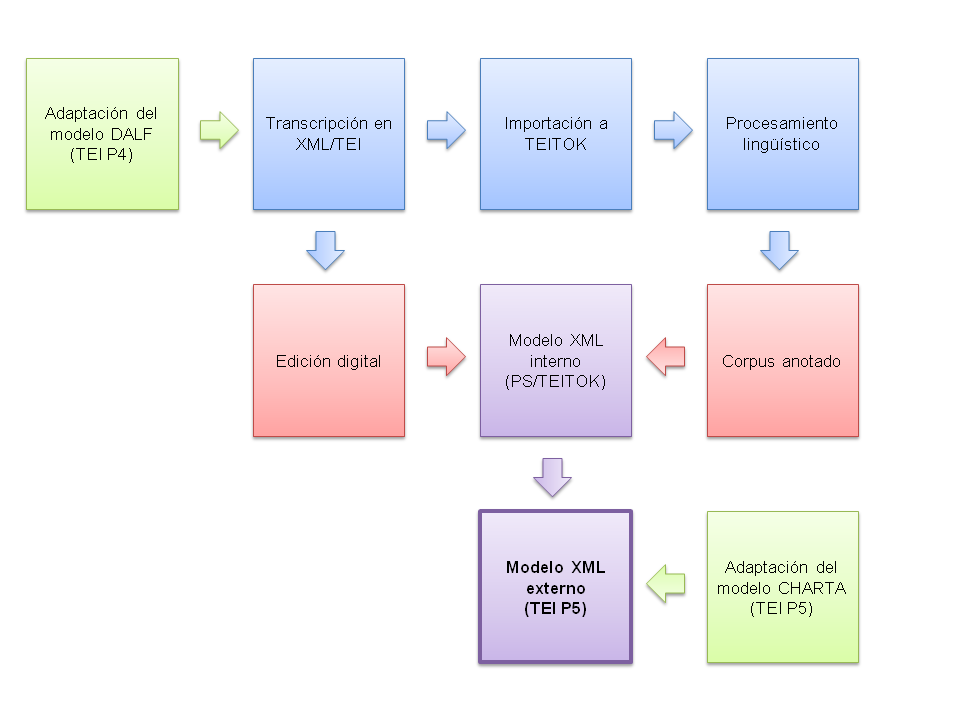
Toda la información biográfica relativa a los participantes de las cartas (i.e. autores y destinatarios) se registró inicialmente en un archivo XML externo llamado CDD.xml (con letras mayúsculas), siglas de CARDS Demographic Database. Este archivo XML toma su nombre del proyecto CARDS, predecesor de PS, y fue creado siguiendo el estándar de marcación TEI P4. Posteriormente, y una vez terminado el proyecto PS, se generó de manera automática una versión en TEI P5 llamada cdd.xml (con letras minúsculas). Esta versión en TEI P5 se puede descargar desde la página web de PS y es la que se documenta a continuación.
4.2.2. La lista de participantes
La lista completa de participantes se incluye dentro del elemento <listPerson>. Dentro de este elemento, la ficha biográfica de cada participante se incluye en su correspondiente elemento <person>, que presenta la siguiente estructura esquemática:
<person>
<persName>
<name/>
</persName>
<affiliation/>
<birth/>
<death/>
<education type="SLA"/>
<event>
<desc/>
</event>
<faith/>
<floruit/>
<langKnowledge>
<langKnown/>
</langKnowledge>
<nationality type="birthplace"/>
<residence type="primary"/>
<residence type="secondary"/>
<socecStatus/>
<state type="marriage">
<p/>
</state>
<trait>
<desc/>
</trait>
</person>
Al rellenar los datos de cada participante se han aplicado los siguientes criterios con carácter general:
- Todas las palabras se escriben con minúscula inicial, excepto los topónimos y antropónimos.
- Antes del cierre de cada elemento no se utiliza punto final.
- Los diferentes items de información dentro de un mismo elemento se separan por punto y coma.
- El orden de aparición de los elementos dentro de <person> es inalterable.
4.2.2.1. Información general
El elemento <person> es el elemento principal de la ficha biográfica, ya que incluye el resto de elementos biográficos de cada participante. Ademas, consta de cuatro atributos que presentan la siguiente información general:
- xml:id: código único asignado a cada participante
- role: rol del participante, que solo admite tres valores:
- author: autor de carta(s)
- addressee: destinatario de carta(s)
- author/addressee: autor y destinatario de carta(s)
- sex: sexo del participante, que solo admite tres valores:
- m: masculino
- f: femenino
- u: desconocido
- n: lengua en que el participante escribió o recibió cartas. Solo admite dos valores:
<person n="es" role="addressee" sex="m"
xml:id="JP13">
</person>
4.2.2.2. Nombre
El nombre completo del participante se incluye en el elemento <persName> dentro de un elemento <name>
<persName>
<name>Marcelina Díez de Cuesta</name>
</persName>
Para la redacción del nombre del participante se han establecido las siguientes pautas:
- Ser lo más completo posible
- Estar escrito con ortografía modernizada
- No incluir títulos ni fórmulas de tratamiento: don, señor, licenciado, conde, duque...
- Si el participante tenía algún apodo, se sitúa al final del nombre y del modo siguiente
<name>Maria da Cruz, alias Maria de Jesus</name>
- Si el participante usaba un nombre falso y sabemos el nombre verdadero, dentro de <name> se cubre solo el nombre verdadero. En el elemento <event> se deja constancia de que usaba un nombre falso:
<event>
<desc>usaba el pseudónimo de José Sáez Cantos</desc>
</event>
- En el caso de cartas heterógrafas o delega gráfica, la ficha biográfica que se debe cubrir es siempre la del autor mental, no la del escriba.
4.2.2.3. Relaciones de parentesco
El elemento <affiliation> se utiliza para dejar constancia de las relaciones de parentesco del participante.
Ejemplo 1:
<affiliation>hermano de Francisco Pérez; nieto de Rafael Narciso</affiliation>
Ejemplo 2:
<affiliation>filha de Gaspar Simões e de Domingas João; neta pelo lado paterno de Simão
Gonçalves e de Ana Gaspar; neta pelo lado materno de João Afonso e de Ana
Fernandes</affiliation>
Las relaciones de amistad del participante se incluyen en el elemento <event>. Las relaciones matrimoniales se incluyen en el elemento <state>
4.2.2.4. Nacimiento y muerte
Las fechas de nacimiento y muerte del participante se establecen mediante los elementos <birth> y <death>, respectivamente. Se trata en ambos casos de elementos vacíos. Pueden contener los atributos siguientes:
- cert: grado de certeza sobre la fecha aportada, que admite dos valores:
- high: grado alto de certeza
- low: grado bajo de certeza
- when: fecha aportada
- notBefore: fecha extrema inicial cuando se aporta un intervalo
- notAfter: fecha extrema final cuando se aporta un intervalo
Si se conoce la fecha completa, se coloca en el orden yyyy-mm-dd. En el caso de manejar un intervalo con fechas extremas, no se utiliza el atributo cert. Se recogen a continuación algunos ejemplos:
Ejemplo 1: fecha completa con grado alto de certeza.
<birth cert="high" when="1780-10-13"/>
Ejemplo 2: fecha con grado bajo de certeza.
<birth cert="low" when="1585"/>
Ejemplo 3: intervalo de fechas extremas.
<birth notAfter="1776" notBefore="1766"/>
4.2.2.5. Conocimiento de segundas lenguas
Si el participante conoce segundas lenguas, esta información se incluye en el elemento <education>. Este elemento contiene siempre un atributo type con el valor SLA (Second Language Acquisition). Cada lengua va asociada a un código: latín (LT); francés (FR); español (ES); inglés (EN); árabe (AR); italiano (IT); griego (GR); alemán (AL). Para rellenar este elemento, se recurre siempre al código correspondiente.
<education type="SLA">LT</education>
Si el participante conoce varias lenguas, los códigos correspondientes se separan por punto y coma.
<education type="SLA">ES; FR; IT</education>
Cualquier otro tipo de información acerca de la formación educativa o cultural del participante se incluye en el elemento <event>.
4.2.2.6. Episodios biográficos
La información sobre episodios y sucesos relevantes de la vida del participante se incluye en el elemento <event>, que incluye a su vez un elemento <desc>. El texto incluido en <event> se redacta en pasado y los diferentes items de información se separan por punto y coma.
Ejemplo 1:
<event>
<desc>en 1825 fue apresado por intento de extorsión; en 1826 fue degradado para Cabo
Verde por tres años</desc>
</event>
Ejemplo 2:
<event>
<desc>casou em Amesterdão em 1664 com Abigael Nassi; foi para o Recife, via Amesterdão; c.
de 1648, regressou a Amesterdão e esteve entre os primeiros colonos judeus de Curaçao em
1651; proprietário de terras em Caiena; incorporou o grupo de cinco empreendedores judeus
responsáveis pelo estabelecimento de comunidades judaicas nas colónias holandesas do
Caribe em meados do séc. XVII; faleceu em Amesterdão. </desc>
</event>
Las relaciones de amistad del participante también se incluyen en <event> y no en <affiliation>, que se reserva únicamente para relaciones de parentesco:
<event>
<desc>amigo de Manuel Pinto Pereira Sobrinho; o seu amigo foi para o Brasil por oito anos a
trabalho</desc>
</event>
Si la persona fue procesada por algún delito, también se registra en <event>
<event>
<desc>en 1658 fue acusado de un delito de bigamia</desc>
</event>
De ser el caso, también se incluye en este elemento información sobre la formación cultural del participante, particularmente su condición de analfabeto:
<event>
<desc>no sabía leer ni escribir</desc>
</event>
El conocimiento de segundas lenguas, no obstante, se incluye en el elemento <education>.
4.2.2.7. Religión
La información de tipo religioso se incluye en el elemento <faith>:
Ejemplo 1:
<faith>cristão-velho</faith>
Ejemplo 2:
<faith>cristão-novo</faith>
Ejemplo 3:
<faith>judeu</faith>
4.2.2.8. Etapa floreciente
La etapa floreciente del participante se incluye en el elemento <floruit>. En PS se entiende por etapa floreciente aquella en la que el participante escribió y/o recibió cartas. Se trata en un elemento vacío que puede contener los atributos siguientes:
- cert: grado de certeza sobre la fecha aportada, que admite dos valores:
- high: grado alto de certeza
- low: grado bajo de certeza
- when: fecha aportada
- from: fecha inicial cuando se aporta un intervalo
- to: fecha final cuando se aporta un intervalo
- notBefore: fecha extrema inicial cuando se aporta un intervalo
- notAfter: fecha extrema final cuando se aporta un intervalo
El valor de los atributos when, from, to, notBefore y notAfter es siempre un año (sin mes ni día). En el caso de manejar un intervalo con fechas extremas, no se utiliza el atributo cert. Se recogen a continuación algunos ejemplos:
Ejemplo 1: fecha con grado alto de certeza.
<floruit cert="high" when="1711"/>
Ejemplo 2: fecha con grado bajo de certeza.
<floruit cert="low" when="1603"/>
Ejemplo 3: intervalo de fechas con grado alta de certeza.
<floruit cert="high" from="1766" to="1771"/>
Ejemplo 4: intervalo de fechas con grado bajo de certeza.
<floruit cert="low" from="1600" to="1603"/>
Ejemplo 5: intervalo de fechas extremas.
<floruit notAfter="1679" notBefore="1670"/>
4.2.2.9. Lengua nativa
Para marcar la lengua nativa del participante se hace uso del elemento <langKnown> incluido dentro del elemento <langKnowledge>. El elemento <langKnown> es un elemento vacío que incluye un atributo tag. El valor de este atributo será el código de la lengua que corresponda: la (latín), es (español), pt (portugués), fr (francés)...
<langKnowledge>
<langKnown tag="fr"/>
</langKnowledge>
Solo es necesario informar de la lengua materna cuando el valor del atributo tag no coincide con el valor del atributo n incluido en el elemento <person>. En otras palabras, la información de la lengua materna del participante solo es relevante cuando no coincide con la lengua en que escribe y/o recibe cartas.
4.2.2.10. Nacionalidad y residencia
El lugar de nacimiento del participante se incluye en el elemento <nationality>, que incluye siempre un atributo type con el valor birthplace.
<nationality type="birthplace">Portugal, Lisboa</nationality>
El lugar de residencia del participante se incluye en el elemento <residence>. Se han considerado dos elementos <residence>: uno con el valor primary en el atributo type y otro con el valor secondary en el atributo type. El primero hace referencia a la residencia habitual del participante; el segundo hace referencia a otra residencia temporal, si la hubiere.
<residence type="primary">España, Badajoz, Zafra</residence>
<residence type="secondary">España, Sevilla</residence>
Solo se rellena una residencia habitual y una residencia secundaria. El resto de residencias secundarias, si las hubiera, se incluyen en el elemento <event>. Las estancias en prisión no se consideran residencia secundaria; también se incluyen en el elemento <event>:
<event>
<desc>tuvo como residencias secundarias Madrid, Toledo y París</desc>
</event>
<event>
<desc>no sabía leer; acusada de tratos ilícitos e infidelidad en 1828; condenada en 1829 a
cuatro meses de prisión; presa en la cárcel real de Corte de la Chancillería de Valladolid
en 1829; acusada nuevamente de tratos ilícitos y adulterio en 1830; condenada en 1831 a
dos años de reclusión y al pago de las costas; presa en la cárcel real de Corte de la
Chancillería de Valladolid desde finales de 1830 hasta 1833</desc>
</event>
El contenido textual de los elementos <nationality> y <residence> se rige por unas pautas sistemáticas de redacción. Estas pautas son las mismas que se aplican para rellenar el contenido del elemento <placeName> dentro de <location> (cf. 2.3.3.2. Lugar de origen y destino).
Los elementos <nationality> y <residence> pueden contener un atributo key que informa de las coordenadas geográficas del lugar en cuestión. La declaración de coordenadas viene dada por dos números separados por espacio, correspondientes a la latitud y longitud de acuerdo con el Sistema Geodésico Mundial (WGS84)>
Ejemplo 1:
<nationality key="37.627609 -0.997090"
type="birthplace">España, Murcia,
Cartagena</nationality>
Ejemplo 2:
<residence key="-19.568546 -65.759129"
type="primary">Bolivia, Potosí</residence>
Ejemplo 3:
<residence key="39.023333 -7.814597"
type="secondary">Portugal, Avis, Ervedal</residence>
4.2.2.11. Clasificación social y ocupación
Los rangos, ocupaciones u oficios desempeñados por el participante se incluyen dentro del elemento <socecStatus>
<socecStatus key="ordinary">vendedeira de pão</socecStatus>
Si solo se conoce la ocupación de un familiar directo, y no la del propio participante, se utiliza dicha información para rellenar este apartado:
Ejemplo 1:
<socecStatus key="ordinary">mujer de zapatero</socecStatus>
Ejemplo 2:
<socecStatus key="ordinary">viuda de marinero</socecStatus>
Ejemplo 3:
<socecStatus key="ordinary">hijo de labrador</socecStatus>
El elemento <socecStatus> contiene un atributo key que informa acerca de la clasificación social del participante. Esta clasificación está basada en el tribunal al que cada individuo podía acogerse en la Edad Moderna en función de su condición jurídica. Se han considerado nueve posibilidades, cada uno con su respectivo valor dentro del atributo key:
- nobility: nobleza
<socecStatus key="nobility">conde de Aranda; presidente del Consejo de
Castilla</socecStatus>
- ecclesiastical: clero
<socecStatus key="ecclesiastical">párroco de la iglesia Santa María la Mayor</socecStatus>
- inquisitorial: miembros del Santo Oficio
<socecStatus key="inquisitorial">médico; familiar del Santo Oficio</socecStatus>
- military: militares
<socecStatus key="military">soldado</socecStatus>
- knightlyOrders: caballeros de hábito
<socecStatus key="knightlyOrders">caballero de la Orden de Calatrava</socecStatus>
- universitary: universitarios
<socecStatus key="universitary">estudiante; colegial del Colegio Mayor de San
Ildefonso</socecStatus>
- ordinary: estado llano
<socecStatus key="ordinary">labrador</socecStatus>
- slave: esclavos
<socecStatus key="slave">esclavo</socecStatus>
- unknown: desconocido
<socecStatus key="unknown"/>
Dentro de la categoría ordinary se incluyen los gremios y otras corporaciones como colegios profesionales o cofradías devocionales. Aunque este tipo de asociaciones gozaron de ciertos privilegios durante el Antiguo Régimen, éstos no tenían carácter estrictamente jurisdiccional, por lo que no se han considerado como categoría diferenciada. También entran en la categoría ordinary (y no en slave) los libertos, puesto que al ser declarados libres varía su condición jurídica y pasan a ser un miembro más del estado llano.
Los cargos y títulos también son incluidos dentro de <socecStatus>:
<socecStatus key="universitary">licenciado</socecStatus>
4.2.2.12. Estado civil
El estado civil del participante se incluye en el elemento <state> dentro de un elemento <p>.
Ejemplo 1:
<state type="marriage">
<p>casada con Gaspar de Cerqueira</p>
</state>
Ejemplo 2:
<state type="marriage">
<p>viudo de Isabel Pérez</p>
</state>
Ejemplo 3:
<state type="marriage">
<p>soltero</p>
</state>
En caso de que sepamos el estado civil, pero no el cónyuge, se registra solo el estado civil.
<state type="marriage">
<p>viuda</p>
</state>
4.2.2.13. Descripción física
Los rasgos físicos del participante se incluyen en el elemento <trait> dentro de <desc>
<trait>
<desc>cuerpo delgado, moreno, pelo de color castaño, chupado de cara, ojos
pardos</desc>
</trait>
4.2.2.14. Ejemplo de ficha biográfica
Ejemplo completo de ficha biográfica tomado del participante Pedro Pablo Díez:
<person age="36" n="es"
role="author/addressee" sex="m" xml:id="PPD1">
<persName>
<name>Pedro Pablo Díez</name>
</persName>
<affiliation>hijo de Domingo Antonio Díez y de Ana María Sánchez; padre de Paula
Díez</affiliation>
<birth cert="high" when="1673"/>
<death/>
<education type="SLA"/>
<event>
<desc>estudió gramática en Alcalá de Henares; en 1711 fue condenado por la Inquisición por
el delito de iluso e iludente</desc>
</event>
<faith>cristiano viejo</faith>
<floruit cert="high" from="1706" to="1709"/>
<langKnowledge>
<langKnown tag="es"/>
</langKnowledge>
<nationality key="40.526008 -2.823433"
type="birthplace">España, Guadalajara,
Alhóndiga</nationality>
<residence key="39.902922 -3.625574"
type="primary">España, Toledo, Yepes</residence>
<residence type="secondary"/>
<socecStatus key="ordinary">boticario</socecStatus>
<state type="marriage">
<p>primer matrimonio con Teresa Pérez Vázquez; casado desde 1701 con Petronila
González</p>
</state>
<trait>
<desc>de buen cuerpo, algo calvo, pelo castaño oscuro poco poblado, hoyo en la
barba</desc>
</trait>
</person>
Ejemplo completo de ficha biográfica tomado del participante Maria de Fonseca:
<person n="pt" role="author" sex="f"
xml:id="MF3">
<persName>
<name>Maria da Fonseca</name>
</persName>
<affiliation>filha de Pedro Dias e de Antónia Rodrigues; mãe de Mariana; irmã de Manuel
Rodrigues</affiliation>
<birth/>
<death/>
<education type="SLA"/>
<event>
<desc>casou na freguesia de São José (Lisboa) a 9 de outubro de 1634; deste matrimónio
teve uma filha, que faleceu ainda criança; tinha tenda de frutas da terra, pão e louça;
fugiu do primeiro marido, o qual, depois, voltou a casar, razão pela qual ameaça acusá-lo
de bigamia</desc>
</event>
<faith/>
<floruit cert="high" when="1661"/>
<langKnowledge>
<langKnown tag="pt"/>
</langKnowledge>
<nationality key="38.722268 -9.139338"
type="birthplace">Portugal, Lisboa</nationality>
<residence key="38.722268 -9.139338"
type="primary">Portugal, Lisboa, São José</residence>
<residence key="-22.906538 -43.173523"
type="secondary">Brasil, Rio de Janeiro</residence>
<socecStatus key="ordinary">tendeira</socecStatus>
<state type="marriage">
<p>casada com Pascoal Coutinho</p>
</state>
<trait>
<desc>alta de corpo, boa estatura, magra e alva; aparentava ter entre 45 e 50 anos</desc>
</trait>
</person>